Caffe-MPI是基于BVLC的Caffe框架,利用MPI并行编程技术实现的集群并行版Caffe。在对伯克利版 本Caffe进行大规模图像训练时性能需求的基础上,通过对数据并行处理实现多个任务并行执行,最大限度提高Caffe训 练数据时的性能。Inspur Caffe-MPI可运行于大规模集群平台,包括GPU集群平台、KNL集群平台、及CPU集群平台。 Caffe-MPI具有良好的继承性与易用性,完全保留了原始Caffe架构的特性,其特点是高性能和高可扩展性。
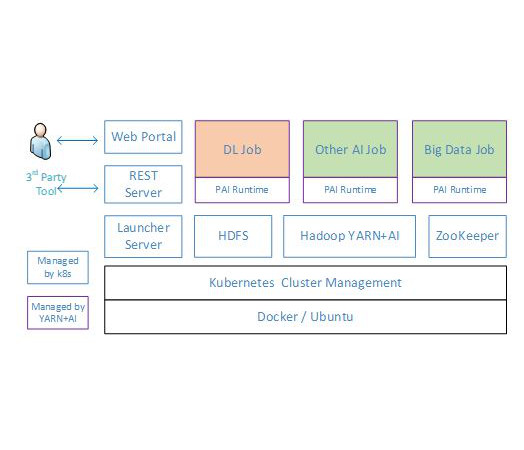
完整的HPC系统解决方案
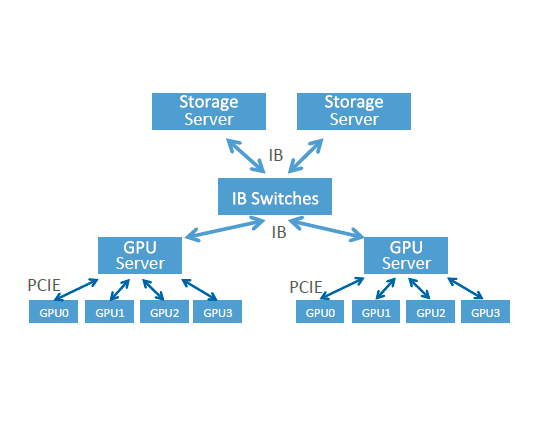
硬件系统采用Lustre存储+IB网络+GPU集群,实现较高的IO吞吐、IB高速互联及GPU大规模并行训练。
")
高性能与高可扩展性
可以采用多机多卡同时训练,训练性能较BVLC单GPU卡性能实现大幅提升,可以部署到大规模训练平台上,实现对大规模数据样本的训练。对于GoogleNet模型,Caffe-MPI较单GPU版本性能提升10倍以上。
")
良好的继承性与易用性
完全保留了原始Caffe架构的特性,具备上手快、速度快、模块化、开放性等众多特性,为用户提供了最佳的应用体验。目前,浪潮推动的开源Caffe-MPI已受到中国、印度、美国等众多公司和研究机构的关注。 随着人工智能的不断发展,只存在于科幻电影中的一切已经离我们越来越近。如果有一天算法能够突破人为的限定,与人所在的世界交互,真正的人工智能就会到来。而在这一过程中,深度学习和超级计算机将发挥至关重要的作用。
")
Copyright © 2019-2024 青岛希诺智能科技有限公司版权所有 备案号:鲁ICP备19042003号-1
技术支持:微动力网络