


事实上,随着人工智能技术的快速发展,各种深度学习框架层出不穷,为了提高效率,更好地让人工智能快速落地,很多企业都很关注深度学习训练的平台化问题。例如,如何提升GPU等硬件资源的利用率?如何节省硬件投入成本?如何支持算法工程师更方便的应用各类深度学习技术,从繁杂的环境运维等工作中解脱出来?等等。
创建了一个深度定制和优化的人工智能集群管理平台,让人工智能堆栈变得简单、快速、可扩展。
● 为深度学习量身定做,可扩展支撑更多AI和大数据框架
通过创新的PAI运行环境支持,几乎所有深度学习框架如CNTK、TensorFlow、PyTorch等无需修改即可运行;其基于Docker的架构则让用户可以方便地扩展更多AI与大数据框架。
● 容器与微服务化,让AI流水线实现DevOps
100%基于微服务架构,让AI平台以及开发便于实现DevOps的开发运维模式。
● 支持GPU多租,可统筹集群资源调度与服务管理能力
在深度学习负载下,GPU逐渐成为资源调度的关键,提供了针对GPU优化的调度算法,丰富的端口管理,支持Virtual Cluster多租机制,可通过Launcher Server为服务作业的运行保驾护航。
● 提供丰富的运营、监控、调试功能,降低运维复杂度
为运营人员提供了硬件、服务、作业的多级监控,同时开发者还可以通过日志、SSH等方便调试作业。
● 兼容AI开发工具生态
平台实现了与Visual Studio Tools for AI等开发工具的深度集成,用户可以一站式进行AI开发。
支持多种深度学习、机器学习及大数据任务,可提供大规模GPU集群调度、集群监控、任务监控、分布式存储等功能,且用户界面友好,易于操作。
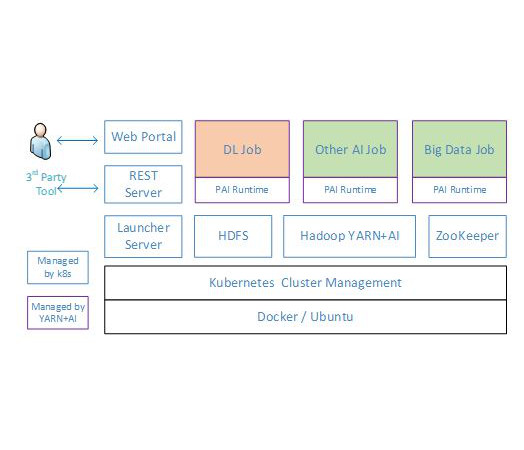
架构如下图所示,用户通过Web Portal调用REST Server的API提交作业(Job)和监控集群,其它第三方工具也可通过该API进行任务管理。随后REST Server与Launcher交互,以执行各种作业,再由Launcher Server处理作业请求并将其提交至Hadoop YARN进行资源分配与调度。可以看到,OpenPAI给YARN添加了GPU支持,使其能将GPU作为可计算资源调度,助力深度学习。其中,YARN负责作业的管理,其它静态资源(下图蓝色方框所示)则由Kubernetes进行管理。
")
Copyright © 2019-2024 青岛希诺智能科技有限公司版权所有 备案号:鲁ICP备19042003号-1
技术支持:微动力网络





